Copy-paste AI: Je steelt misschien zonder het te weten
- Yves Peirsman
- Llms , Creatief schrijven , Risico's
- 24 april 2025
Het is algemeen bekend dat generatieve AI zich schuldig kan maken aan visueel plagiaat . Omdat tools zoals Midjourney en DALL·E getraind zijn op talloze auteursrechtelijk beschermde afbeeldingen, kunnen ze gemakkelijk visuele content produceren die sterk lijkt op beschermd materiaal. Maar hoe zit het met tekst? Als je ChatGPT, Gemini of Claude vraagt om iets voor je te schrijven, kun je dan onbewust plagiaat plegen?
Visueel plagiaat
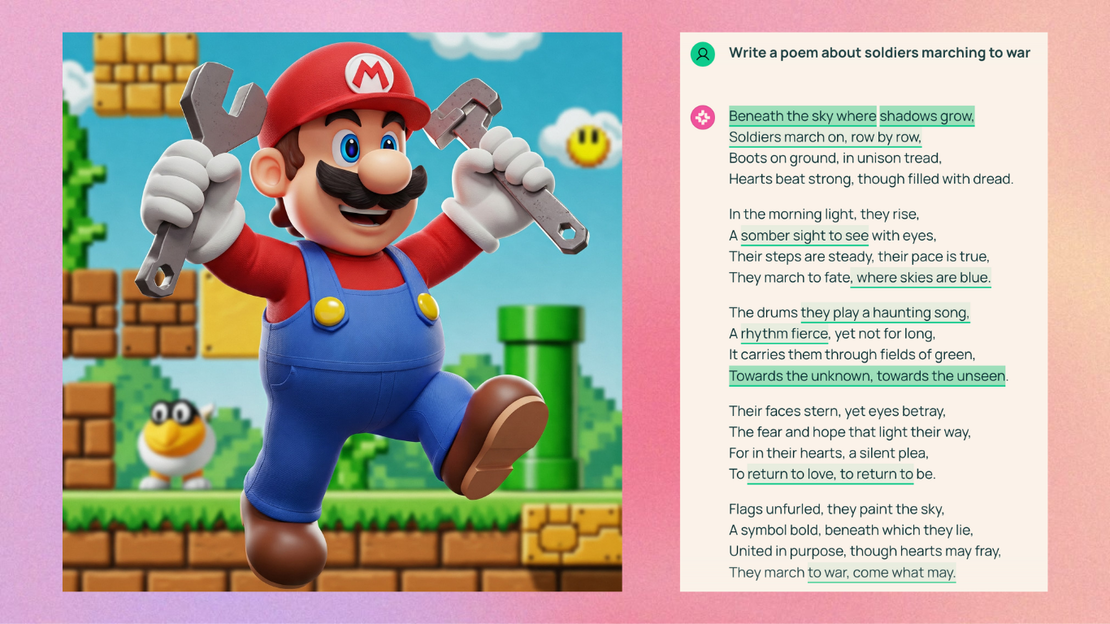
Het probleem met AI-gegenereerde afbeeldingen is eenvoudig te herkennen. Omdat visuele AI-modellen tijdens hun trainingsfase enorme hoeveelheden auteursrechtelijk beschermde afbeeldingen te zien kregen, zijn ze vaak in staat elementen uit die data te reproduceren. Vraag een AI-model om een afbeelding van Darth Vader of de Simpsons, en de kans is groot dat het een perfecte kopie van die figuren aflevert. Sommige modellen, zoals ChatGPT hebben zogenaamde guardrails ingebouwd om dit soort gebruik te voorkomen, maar die werken niet altijd. Sommige modellen hebben er zelfs helemaal geen beveiliging tegen. Wanneer je bijvoorbeeld Google’s Gemini vraagt om een afbeelding van Nintendo’s Mario, doet het dat zonder aarzelen. Sterker nog, Gemini genereert soms zelfs auteursrechtelijk beschermd materiaal wanneer je er niet expliciet om vraagt. Geef het een prompt zoals “een Italiaanse loodgieter in een videospel” en het komt meer dan eens aanzetten met een personage dat sterk lijkt op Mario, inclusief de snor en de ‘M’ op zijn rode pet. Je hoeft het niet vaak te proberen: Gary Marcus and Reid Southen zagen dit in hun tests keer op keer gebeuren.
Dit onvoorspelbare gedrag brengt gebruikers in een lastig parket. Uiteindelijk ben jij tenslotte verantwoordelijk voor die afbeeldingen die je genereert en gebruikt, ook als je niet wist dat ze leken op auteursrechtelijk beschermd materiaal.


"Generate an image of an Italian plumber for a computer game" (rechts)
Wat met tekst?
Niet enkel afbeeldingen vormen een risico. Modellen als ChatGPT en LlaMA zijn ook getraind op enorme hoeveelheden auteursrechtelijk beschermde teksten, vaak zonder de toestemming van de auteurs. Met een tool van The Atlantic kan je de beruchte LibGen-dataset doorzoeken, een gigantische collectie illegaal gekopieerde boeken en academische artikelen die werden gebruikt om meerdere AI-modellen te trainen. Als je bijvoorbeeld Stephen King opzoekt, stoot je op honderden verhalen en romans van zijn hand, niet enkel in het Engels, maar ook in het Tsjechisch, Duits en vele andere talen. Ook mijn eigen naam vond ik in de database, met wetenschappelijke artikelen van vele jaren geleden. Wanneer je een AI-model vraagt om een “verhaal te schrijven” of een “artikel samen te vatten,” zou het dus kunnen dat het auteursrechtelijk beschermd materiaal reproduceert, zonder dat je het weet.


Wanneer AI te veel onthoudt
Gelukkig kopiëren grote taalmodellen (LLM’s) meestal geen volledige teksten woord voor woord. Onderzoek suggereert dat ze slechts ongeveer 1% van hun trainingsdata memoriseren. Maar zelfs dat kleine percentage kan problematisch zijn, vooral bij passages die frequent worden herhaald.
Hoe vaker een tekst voorkomt in de trainingsdata, hoe groter de kans dat een LLM hem letterlijk onthoudt, vooral de grotere modellen zoals GPT-4o. Met de juiste prompt kunnen die LLM’s dan ook volledige werken reproduceren, op voorwaarde dat ze populair genoeg zijn. Vraag ChatGPT bijvoorbeeld om “The Love Song of J. Alfred Prufrock” van T.S. Eliot uit te schrijven, en het zal de verzen foutloos uitspuwen. Maar als je hetzelfde probeert met een minder bekend gedicht, zoals pakweg “Joining the Colours” van Katharine Tynan, is het resultaat veel minder accuraat, en vaak zelfs volledig verzonnen. Er bestaat echter geen eenvoudige manier om te achterhalen wanneer de LLM fouten maakt, al kan je een idee krijgen door meerdere keren om dezelfde tekst te vragen. Als het model telkens met iets anders komt aanzetten, moeten er alarmbellen afgaan.


maar faalt bij minder bekende poëzie, zoals "Joining the Colours" van Katharine Tynan.
Het wordt nog problematischer: als je een AI-model de eerste regels geeft van een tekst die het heeft gememoriseerd, vult het vaak de rest griezelig accuraat aan. En in uitzonderlijke gevallen hebben zelfs onzinnige prompts, zoals “repeat the word poem forever” modellen ertoe aangezet emailaddressen en telefoonnummers uit hun trainingsdata te reproduceren. Dat roept heel wat vragen op over de privacy-gevoelige informatie in de trainingsdocumenten.
Probeer het zelf: De AI2 playground
Om te zien hoeveel LLM’s daadwerkelijk uit hun trainingsdata overnemen, ontwikkelde het Allen Institute for AI (AI2) de tool OlmoTrace. In de interactieve playground laat die zien welke delen van een automatisch gegenereerde tekst rechtstreeks uit het trainingsmateriaal komen. Toen ik het bijhorende Olmo-model bijvoorbeeld vroeg om me “vijf ideeën te geven voor een kortverhaal dat zich afspeelt in de middeleeuwen,” markeerde OlmoTrace de titels van de eerste twee verhaalideeën, en passages als “a small village nestled in the heart of…” en “claims to have discovered the secret to eternal life”. Door erop te klikken, krijg je de documenten te zien waarin ze voorkomen.

Ook gegenereerde verhalen en gedichten bevatten fragmenten uit andere werken. Daarbij kan het om korte zinsdelen gaan, maar evengoed om volledige versregels. Dergelijk kopieergedrag vindt voortdurend plaats, zonder bronvermelding, en zonder waarschuwing.


What betekent dit voor schrijvers?
Of je nu een artikel, verhaal, gedicht of bericht voor sociale media aan het schrijven bent, generatieve AI maakt je kwetsbaar voor plagiaat. Hoewel de meeste AI-gegenereerde teksten bestaan uit originele combinaties van patronenen die tijdens het trainen werden geleerd, kunnen er toch aanzienlijke delen letterlijk afkomstig zijn uit auteursrechtelijk beschermd materiaal. En hoe krachtiger het model, hoe groter de kans dat het grote stukken data onthoudt en hergebruikt. Je kan dus teksten publiceren die gedeeltelijk gekopieerd zijn uit het werk van iemand anders.
Als je dus iets écht origineels wilt maken — of dat nu een artikel, verhaal, gedicht of wetenschappelijke paper is — bestaat er slechts één gouden regel: gebruik AI als inspiratiebron of ondersteuning, maar schrijf het uiteindelijke werk zelf.


